
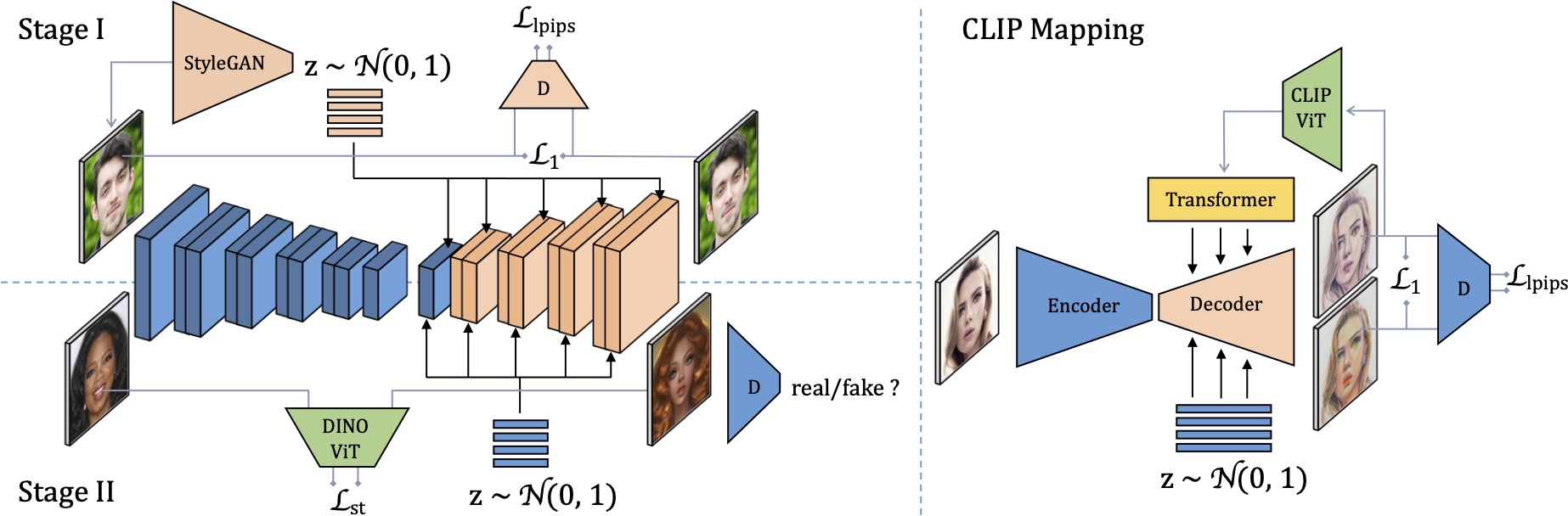
In this work, we introduce a new approach for face stylization. Despite existing methods achieving impressive results in this task, there is still room for improvement in generating high-quality artistic faces with diverse styles and accurate facial reconstruction. Our proposed framework, MMFS, supports multi-modal face stylization by leveraging the strengths of StyleGAN and integrates it into an encoder-decoder architecture. Specifically, we use the mid-resolution and high-resolution layers of StyleGAN as the decoder to generate high-quality faces, while aligning its low-resolution layer with the encoder to extract and preserve input facial details. We also introduce a two-stage training strategy, where we train the encoder in the first stage to align the feature maps with StyleGAN and enable a faithful reconstruction of input faces. In the second stage, the entire network is fine-tuned with artistic data for stylized face generation. To enable the fine-tuned model to be applied in zero-shot and one-shot stylization tasks, we train an additional mapping network from the large-scale Contrastive-Language-Image-Pre-training (CLIP) space to a latent w+ space of fine-tuned StyleGAN. Qualitative and quantitative experiments show that our framework achieves superior performance in both one-shot and zero-shot face stylization tasks, outperforming state-of-the-art methods by a large margin.
@article{li2023multimodal,
title={Multi-Modal Face Stylization with a Generative Prior},
author={Mengtian Li and Yi Dong and Minxuan Lin and Haibin Huang and Pengfei Wan and Chongyang Ma},
journal = {Computer Graphics Forum},
year={2023}
}